比较完整的Hadoop应用jar包,包括入口程序,任务和帮助类3部分就够了
1. 我们在项目的包的顶级放一个入口程序
如 cn.pconline.ad.analytics3.Analyser,入口程序里面有一个ProgramDriver,把任务类加在里面就可以通过命令 hadoop jar Analyser3.0.jar SumPvClick? 执行
public static void main(String argv[]) throws Exception {
int exitCode = -1;
ProgramDriver pgd = new ProgramDriver();
try {
pgd.addClass("CombineADRawFile", CombineADRawFile.class, "");
pgd.addClass("SumPvClick", SumPvClick.class, "");
....
2. hadoop任务是程序包的核心
我们的做法是写一个实现Tool接口的基类,其他的任务继承这个基类,有些公共的方法就不用每个重复
public abstract class JobBase implements Tool
在每个job里增加main函数,使用 ToolRunner?.run 方法调用,这样有些系统的参数如map数量,系统就会先保存到conf里面
传给run的arg都是经过GenericOptionsParser过虑的,在run的方法里面我们可以配置任务各部分需要的类
public static int main(String[] args) throws Exception {
return ToolRunner.run(new Configuration(), new RefererUniq(), args);
}
@Override
public int run(String[] args) throws Exception {
Job job = new Job(conf);
job.setJarByClass(this.getClass());
job.setJobName(jobName);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
。。。。
FileOutputFormat.setOutputPath(job, new Path(userArgs[ARGNAME.WORK.ordinal()]));
job.setMapperClass(MyMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
boolean success = job.waitForCompletion(true);
}
提醒一下新的hadoop mapreduce类在包 org.apache.hadoop.mapreduce.*下
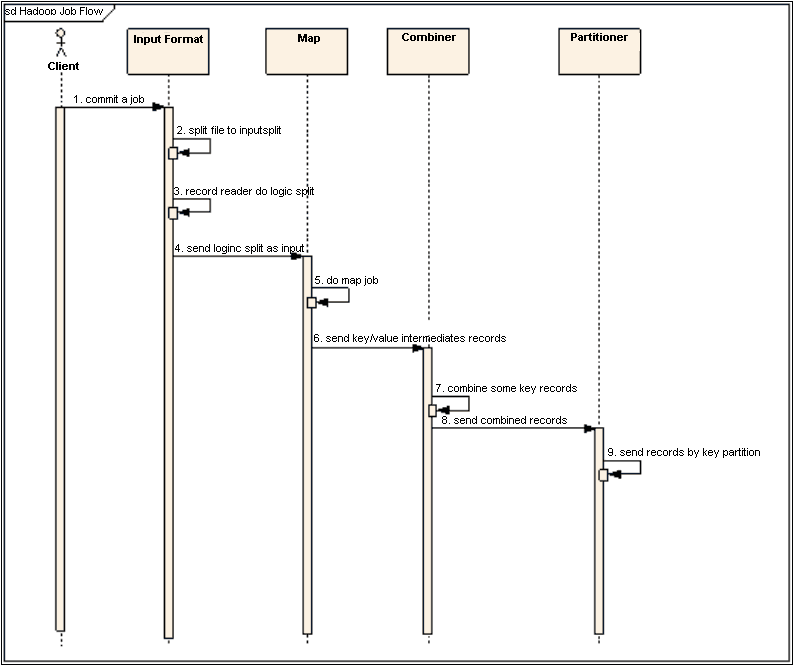
每个任务的核心是map和reduce,有些类可以使用系统现有的,有些可以项目公用,不过更多的需要每个job里面自己定制,借网上的两张图说明一下map和reduce的流程


InputFormat做Map前的预处理,主要负责以下工作:
验证输入的格式是否符合Configuration的输入定义,这个在实现Map和构建Conf的时候就会知道,不定义可以是Writable的任意子类。
将input的文件切分为逻辑上的输入InputSplit,其实这就是在上面提到的在分布式文件系统中blocksize是有大小限制的,因此大文件会被划分为多个block。
通过RecordReader来再次处理inputsplit为一组records,输出给Map。
RecordReader处理后的结果作为Map的输入,Map执行定义的Map逻辑,输出处理后的key和value对应到临时中间文件。
更多的输入输例子可以看Hadoop常用输入输出
Combiner可选择配置,主要作用是在每一个Map执行完分析以后,在本地优先作Reduce的工作,减少在Reduce过程中的数据传输量。
我们在广告统计pv的时候使用了,这样可以减少总体排序的数量和网络上数据传输量
CombinerClass可以和reduce类相同也可以不同
job.setMapperClass(MyMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
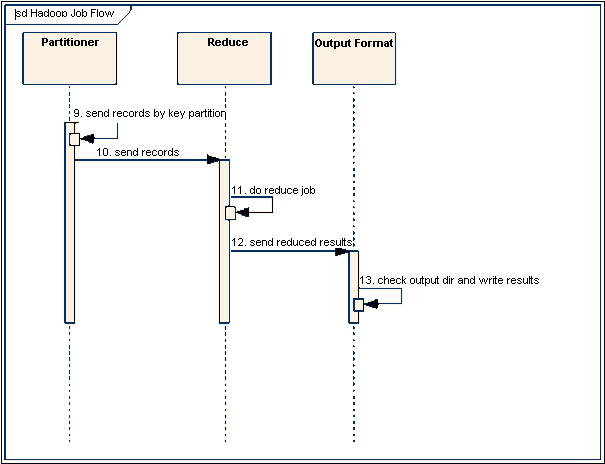
Partitioner可选择配置,主要作用是在多个Reduce的情况下,指定Map的结果由某一个Reduce处理,每一个Reduce都会有单独的输出文件。
主要使用场景是想一次读文件,得到多样的结果,比如读广告的原始文件,希望一次得到所有唯一的ip和唯一的uv可以使用这种
但如果搞得太复杂会影响程序的可读性,增加判断肯定会影响job的速度,有时候我宁愿多读一次输入。
Reduce执行具体的业务逻辑,并且将处理结果输出给OutputFormat。
一个简单的reduce里面,要注意的是reduce的迭代器只能读取一次Iterable<IntWritable?> values,如果你要遍历所有values,要注意会不会OOM。
/**
* 累计value的reducer类
* @param <K>
*/
public static class IntSumReducer<K>
extends Reducer<K, IntWritable, K, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(K key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
OutputFormat的职责是,验证输出目录是否已经存在,同时验证输出结果类型是否如Config中配置,最后输出Reduce汇总后的结果。
除非你要改变hadoop的输出规则,否则建议不需要自己写这部分,使用系统的就可以了,我们曾经试图把输出写到同一个文件上,这样hadoop只能使用单个的reduce
完成job的时间也是极慢的。
更多的输入输例子可以看Hadoop常用输入输出
3.帮助类
帮助类主要是有DFS操作和字符操作的类
值得一提的DFSUtils里面的delete方法做了一些限制和判断,让程序不能删除根目录和一级目录,只要不直接调用filesystem的方法
就不怕用户在输入目录参数(为了方便本地调试,大部分job会使用目录为程序参数)的时候写错目录以致删除了比较重要的目录。
附件是比较完整的程序,有兴趣可以下来看看
Attachments
-
map.jpg
 (13.7 KB) -
added by liaojiaohe 14 years ago.
(13.7 KB) -
added by liaojiaohe 14 years ago.
-
reduce.jpg
(7.8 KB) -
added by liaojiaohe 14 years ago.
-
adAnalytics3.0.zip
(135.9 KB) -
added by liaojiaohe 14 years ago.